Let’s Build Bg2Vec: Final Evaluation - MTEB-Bulgarian and Challenging Examples
Hello and welcome to the fifth and final post in the Bg2Vec series. In this post, we will evaluate if the model we trained in the previous post is performing better for various downstream tasks compared to the original bulgarian model and other multilingual alternatives.
As a reminder, the plan is as follows:
- Part 1 - Overview & Objectives.
- Part 2 - Preparing the training data
- Part 3 - Masked Next Token Prediction training
- Part 4 - SimCSE training
- Part 5 - Evaluation of the resulting text encoder (this post)
The evaluation will be as follows:
- We will evaluate on a small set of hard examples translated from the Echo Embeddings paper.
- We will use the MTEB benchmark
Let’s get started!
Challenging Examples
The challenging examples are triples of sentences where the first two are similar and the third is dissimilar. A good text encoder will have a higher similarity score for the first two sentences compared to the third. To make the task even harder, all three sentences in a triple share the same prefix. This makes it more challenging for the model as it has to rely on the context to distinguish between the similar and dissimilar sentences.
Examples:
| Original | Positive | Negative |
|---|---|---|
| Тя обича да пътува през лятото, особено до студени дестинации, като избягва горещи и пренаселени места | Тя обича да пътува през лятото, специално към хладни места, избягвайки топли и многолюдни райони | Тя обича да пътува през лятото, но предпочита да посещава горещи и оживени туристически места |
| Котката често седи до прозореца, мечтаейки да гони птици и да се наслаждава на топлите слънчеви лъчи. | Котката често седи до прозореца, представяйки си преследването на птици и припичайки се на слънце. | Котката често седи до прозореца, но е твърде мързелива, за да мечтае да гони каквото и да било. |
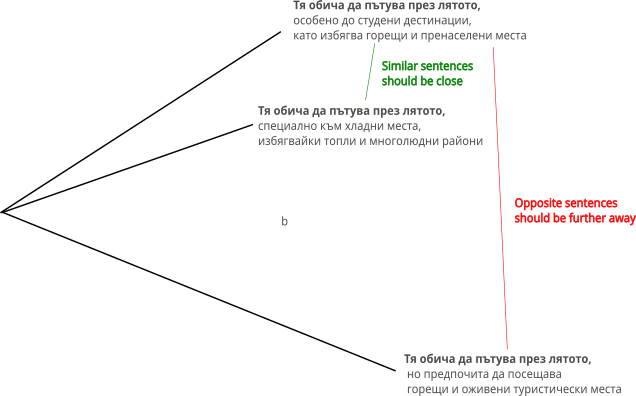
You can find all the examples here
To evaluate the text encoder on this dataset, we define the following metric:
\[\frac{1}{N}\sum_{t \in triples} sim(original_{t},positive_t ) - sim(original_{t}, negative_t)\]Where $sim(a,b)$ is the cosine similarity between the embeddings of $a$ and $b$. This is the mean difference between the similarity of the original sentence with the positive and negative examples.
Applying this methodology, we get the following results:
| Model | score |
|---|---|
| bg2vec | 0.235543 |
| bge-multilingual-gemma2 | 0.164315 |
| e5-mistral-7b-instruct | 0.132534 |
| multilingual-e5-large | 0.0389574 |
| BgGPT-7B-Instruct-v0.2 | 0.0334313 |
| gte-Qwen2-7B-instruct | 0.0259391 |
The results show that the bg2vec model is performing significantly better than the original model(bggpt-7b-instruct) on this task. This suggests that the contrastive finetuning has improved the model’s ability to distinguish between similar and dissimilar sentences.
Massive Text Embedding Benchmark
MTEB is a massive benchmark for measuring the performance of text embedding models on diverse embedding tasks. The benchmark allows us to select tasks based on their type and language.
For our purposes, we will evaluate the bg2vec model on the following tasks:
from mteb import MTEB
import mteb
tasks = mteb.get_tasks(languages=["bul"],task_types=["Retrieval",
"Classification",
"Clustering",
"Reranking",
"PairClassification",
"MultilabelClassification"
])
tasks
> MTEBTasks(BulgarianStoreReviewSentimentClassfication(name='BulgarianStoreReviewSentimentClassfication', languages=['bul']),
LanguageClassification(name='LanguageClassification', languages=['ara', 'bul', 'cmn', '...']),
MultilingualSentimentClassification(name='MultilingualSentimentClassification', languages=['bul']),
SIB200Classification(name='SIB200Classification', languages=['bul']),
SIB200ClusteringFast(name='SIB200ClusteringS2S', languages=['bul']),
BelebeleRetrieval(name='BelebeleRetrieval', languages=['bul', 'eng']),
WikipediaRetrievalMultilingual(name='WikipediaRetrievalMultilingual', languages=['bul']),
MultiEURLEXMultilabelClassification(name='MultiEURLEXMultilabelClassification', languages=['bul']), XNLI(name='XNLI', languages=['bul']),
WikipediaRerankingMultilingual(name='WikipediaRerankingMultilingual', languages=['bul']))
The MultiEURLEXMultilabelClassification caused some memory issues, so I excluded it.
| Task Name | Bg2Vec | BgGPT | bge-multilingual-gemma2 |
|---|---|---|---|
| BulgarianStoreReviewSentimentClassfication | 0.609 | 0.570 | 0.696 |
| LanguageClassification | 0.983 | 0.992 | 0.920 |
| MultilingualSentimentClassification | 0.810 | 0.720 | 0.905 |
| SIB200Classification | 0.718 | 0.758 | 0.769 |
| SIB200ClusteringS2S | 0.262 | 0.319 | 0.391 |
| BelebeleRetrieval | 0.910 | 0.348 | 0.764 |
| WikipediaRetrievalMultilingual | 0.780 | 0.392 | 0.689 |
| XNLI | 0.621 | 0.578 | 0.792 |
| WikipediaRerankingMultilingual | 0.752 | 0.656 | 0.813 |
The results show that the bg2vec model is performing better than the original model on most tasks and particularly better on the retrieval tasks. This suggests that the llm2vec procedure has improved the model’s ability to retrieve relevant information and makes it more suitable for usage as a text encoder.
For better or for worse, we also see that a multilingual model like bge-multilingual-gemma2 is beating the Bulgarian models on most tasks. This suggests that there is still a lot of work ahead of us to improve the Bulgarian models and make them competitive with the best models in the world.
Conclusion
While Bg2Vec did not achieve state-of-the-art performance on the MTEB benchmark for Bulgarian, it has definitely shown improvements
over the original model for the retrieval use cases.
I also learned a lot during this project and I hope you did too! We played around with the Hugging Face ecosystem(transformers, datasets, tokenizers, publishing models, etc.),
learned about LoRA and contrastive learning, and reviewed a lot of code along the way.
If you have any questions, suggestions or feedback, feel free to reach out to me on LinkedIn. Follow we if you’d like to see more content like this in the future.
References & Resources
As side effects of this project, I created the following resources:
- BgWiki - the Bulgarian Wikipedia dataset
- Bg2Vec-MNTP - a MNTP fine-tuned model
- Bg2Vec - the final model we trained in this series
- Bg2Vec Code - the code for this project
Of course, none of this would have been possible without the original work: