Let’s Build Bg2Vec: Bidirectional Masked Next Token Prediction Training
Hello and welcome to the third post in the Bg2Vec series. In this post, we finally get to finetune a LLM.
As a reminder, the plan is as follows:
- Part 1 - Overview & Objectives.
- Part 2 - Preparing the training data
- Part 3 - Masked Next Token Prediction training (this post)
- Part 4 - SimCSE training
- Part 5 - Evaluation of the resulting text encoder
Let us first remind ourselves how the Bi-MNTP training objective combines the more common MLM and NTP objectives: it uses the activations from the previous token to recover the masked tokens. This keeps it close to the next token prediction task, which makes finetuning easier - the finetuning process mostly needs to adapt to the newly introduced bidirectional attention mechanism.
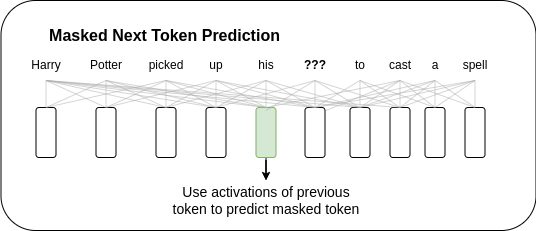
In the next sections, we will examine the finer details of the model training. But first, we need to discuss the relevant hardware!
Note: some code is omitted for brevity. The full code can be found in the notebook
The Hardware
Training LLMs is computationally expensive and we need some really serious hardware. In their experiments, the authors of the LLM2Vec paper used a single A100 GPU with 80GB of VRAM memory. I was only able to get such a powerful GPU on Paperspace Gradient. In periods of high demand, there were no A100 GPUs available, but I was able to get the training running on a A6000 GPU with 48GB of VRAM.
Training the Model
To train the model, we will need the following ingredients:
- The BgGPT model with activated bidirectional attention.
- The training data we prepared in the previous post.
- A data collator that will prepare the input tensors for the model and apply the masking. It depends on the tokenizer, so that it can handle the special tokens correctly.
- A Trainer
Let’s setup all of these components!
Loading the modified model
After we setup some relevant configuration, we can load the model config. Using the model config, the llm2vec library can deduce the modified model class that it needs to load.
from transformers import AutoConfig
config = AutoConfig.from_pretrained(
model_args.model_name_or_path, **config_kwargs
)
model_class = get_model_class(config)
model_class
> llm2vec.models.bidirectional_mistral.MistralBiForMNTP
Note that instead of a regular Mistral model that is used in the original BgGPT model, we are using the MistralBiForMNTP model.
This model will take care of adding bidirectional attention.
Afterwards, we can load the model using the from_pretrained method.
torch_dtype = (
model_args.torch_dtype
if model_args.torch_dtype in ["auto", None]
else getattr(torch, model_args.torch_dtype)
)
model = model_class.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
torch_dtype=torch_dtype,
low_cpu_mem_usage=model_args.low_cpu_mem_usage,
attn_implementation=model_args.attn_implementation,
)
We can now check the structure of the loaded model.
MistralBiForMNTP(
(model): MistralBiModel(
(embed_tokens): Embedding(38000, 4096)
(layers): ModuleList(
(0-31): 32 x ModifiedMistralDecoderLayer(
(self_attn): ModifiedMistralFlashAttention2(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): MistralRotaryEmbedding()
)
(mlp): MistralMLP(
(gate_proj): Linear(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): MistralRMSNorm()
(post_attention_layernorm): MistralRMSNorm()
)
)
(norm): MistralRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=38000, bias=False)
)
And we can also verify that we are not using causal attention:
model.model.layers[0].self_attn.is_causal
> False
So now that we’ve loaded up the pretrained model, we can initialize the finetuning model.
The method is called initialize_peft for “parameter efficient finetuning”. It adds a LoRA (Low Rank Adaptation) layer to each of the model’s attention and MLP layers.
The assumption is that the finetuning process will only need to adjust a small number of parameters and that the adjustment can be approximated using the product of two low-rank matrices.
This has a dramatic effect on the number of parameters that need to be finetuned.
model = initialize_peft(
model,
lora_r=custom_args.lora_r,
lora_alpha=2 * custom_args.lora_r,
lora_dropout=custom_args.lora_dropout,
)
> Model's Lora trainable parameters: trainable params: 41,943,040 || all params: 7,177,179,136 || trainable%: 0.5843944982453898
As you can see, we will only finetune 0.58% of the model’s parameters.
If we inspect a single layer of the model, we can see that the Lora modules are added to the model.
ModifiedMistralDecoderLayer(
(self_attn): ModifiedMistralFlashAttention2(
(q_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(k_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(v_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(o_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(rotary_emb): MistralRotaryEmbedding()
)
(mlp): MistralMLP(
(gate_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=14336, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=14336, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(up_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=14336, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=14336, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(down_proj): lora.Linear(
(base_layer): Linear(in_features=14336, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=14336, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(act_fn): SiLU()
)
(input_layernorm): MistralRMSNorm()
(post_attention_layernorm): MistralRMSNorm()
)
Note the added lora_A and lora_B layers. These hold the Lora parameters that will be finetuned during the training process.
Data Collator
The data collator is a class that will prepare the input tensors for the model. It will apply the masking and padding to the input tensors.
There are a few different strategies for masking the input tokens. According to the LLM2Vec paper, the best strategy is model specific and should be determined by hyperparameter search.
For our purposes, we will use the strategy that they found works best for the Mistral model: all_mask which simply replaces a portion of the input with mask tokens.
from transformers import AutoTokenizer
tokenizer_kwargs = {
"cache_dir": model_args.cache_dir,
"use_fast": model_args.use_fast_tokenizer,
"revision": model_args.model_revision,
"token": model_args.token,
"trust_remote_code": model_args.trust_remote_code,
}
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path, **tokenizer_kwargs
)
## Handle special cases for the mask token
if tokenizer.mask_token is None:
if custom_args.mask_token_type == "blank":
tokenizer.mask_token = "_"
elif custom_args.mask_token_type == "eos":
tokenizer.mask_token = tokenizer.eos_token
elif custom_args.mask_token_type == "mask":
tokenizer.add_tokens(["<mask>"])
tokenizer.mask_token = "<mask>"
else:
raise ValueError(
f"mask_token_type {custom_args.mask_token_type} is not supported."
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorForLanguageModelingWithFullMasking(
tokenizer=tokenizer,
mlm_probability=data_args.mlm_probability
)
We can now call the data_collator to verify that it is masking a portion of the input with the mask token(28730 in our case) and marking the unmasked tokens with -100 so they are ignored by the loss function. We only need to reconstruct the masked tokens.
data_collator( (torch.randint(0, 10, (1, 10)), ))
> {
'input_ids': tensor([[[28730, 6, 9, 28730, 28730, 28730, 28730, 28730, 28730, 4]]]),
'labels': tensor([[[ 4, -100, -100, 8, 0, 4, 7, 0, 5, -100]]])
}
Loading the data
Fortunately, we have already prepared the data in the previous post. We can load it using the datasets.load_from_disk method.
import datasets
tokenized_datasets = datasets.load_from_disk("grouped_512")
train_dataset = tokenized_datasets["train"]
eval_dataset = tokenized_datasets["validation"]
Trainer & Training
The last step is to setup the Trainer. We will use the MNTPTrainer class from the bg2vec library.
trainer = MNTPTrainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics
if training_args.do_eval and not is_torch_tpu_available()
else None,
preprocess_logits_for_metrics=preprocess_logits_for_metrics
if training_args.do_eval and not is_torch_tpu_available()
else None,
)
trainer.add_callback(StopTrainingCallback(custom_args.stop_after_n_steps))
trainer.callback_handler.remove_callback(transformers.integrations.integration_utils.WandbCallback)
We can now train the model using the train method.
Similar to the LLM2Vec paper, we are training the model for 1000 steps (by using the stop_after_n_steps callback).
We are also evaluating every training_args.eval_steps (100) steps.
train_result = trainer.train()
| Step | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| 100 | No log | 5.531438 | 0.068441 |
| 200 | No log | 5.303927 | 0.061439 |
| 300 | No log | 5.198405 | 0.065503 |
| 400 | No log | 5.101719 | 0.066209 |
| 500 | 5.347800 | 5.052471 | 0.064356 |
| 600 | 5.347800 | 4.998785 | 0.065094 |
| 700 | 5.347800 | 4.963090 | 0.065337 |
| 800 | 5.347800 | 4.937549 | 0.065547 |
| 900 | 5.347800 | 4.915112 | 0.064004 |
| 1000 | 4.911200 | 4.890797 | 0.060033 |
Finally, we can save the model and the tokenizer.
model.save_pretrained(output_dir)
We can also push the model to the hub.
if training_args.push_to_hub:
trainer.push_to_hub()
And that’s it! We have successfully trained the model using the Bi-MNTP objective. I have already trained the model and provide a pretrained model via HuggingFace. To load the model, we can use the following code:
from llm2vec import LLM2Vec
model = LLM2Vec.from_pretrained(
base_model_name_or_path="INSAIT-Institute/BgGPT-7B-Instruct-v0.2",
enable_bidirectional=True,
peft_model_name_or_path="mboyanov/bggpt-mntp"
)
Note that at the time of writing, the llm2vec library does not save the language model head! This means that when we reload the model, we will not be taking advantage of the finetuned language model head. Instead, we should only use the model for extracting the text encoding.
In the next post, we will apply the final step in the finetuning process: training using the SimCSE objective.