Let’s Build Bg2Vec: Simple Contrastive Sentence Embeddings Training
Hello and welcome to the fourth post in the Bg2Vec series. In this post, we will apply the final step in the LLM2Vec procedure: finetuning via Simple Contrastive Sentence Embeddings (SimCSE).
As a reminder, the plan is as follows:
- Part 1 - Overview & Objectives.
- Part 2 - Preparing the training data
- Part 3 - Masked Next Token Prediction training
- Part 4 - SimCSE training (this post)
- Part 5 - Evaluation of the resulting text encoder
Let’s proceed to apply the SimCSE method to finetune the Bg2Vec model. SimCSE is a simple contrastive learning method that has been shown to be effective for sentence embeddings. This will make the model useful for RAG and other downstream sentence-level tasks.
Let’s take a moment to review the SimCSE method. Essentially, the idea is quite similar to the CLIP method, but applied to text. In the case of CLIP, we have pairs of image-text data and we train the model to maximize the similarity between the image and text embeddings while minimizing the similarity between the image and text embeddings of different pairs.
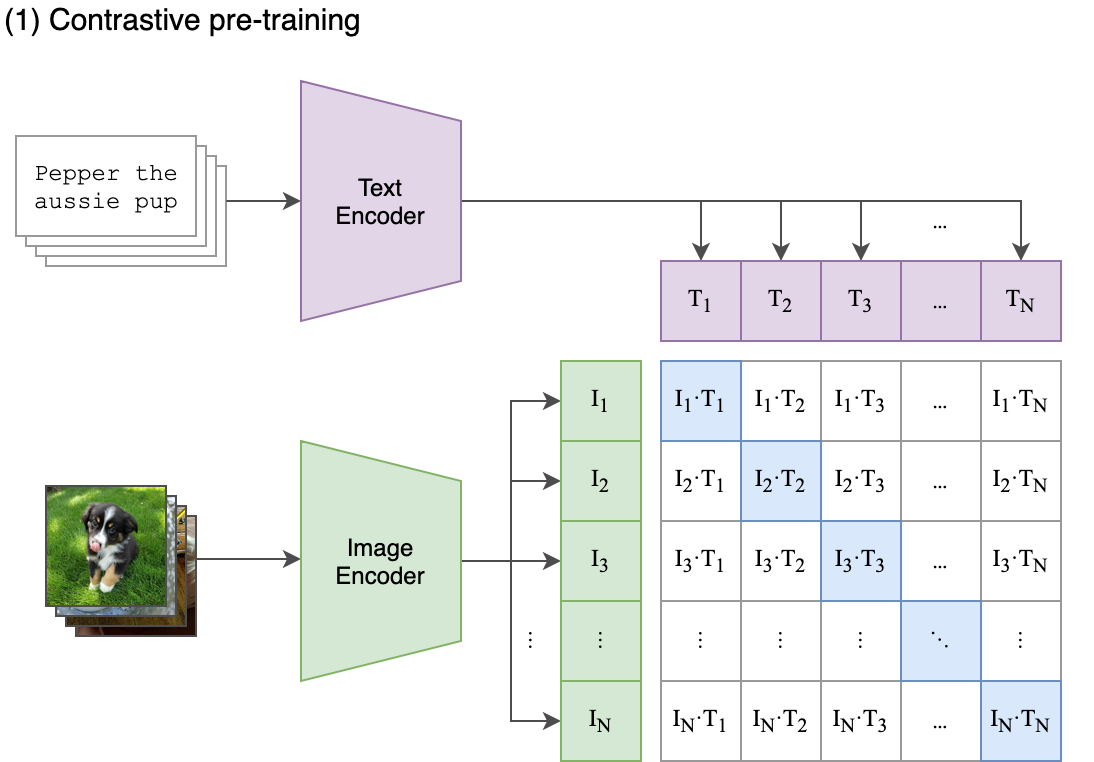
In our case, we don’t have paired data - we only have text. The way that SimCSE works is by taking a sentence and generating two different embeddings for it by passing it through the model with different dropout masks. This results in a paired dataset where we treat the two embeddings of the same sentence as a positive pair and the in-batch negatives as negative pairs. We then train the model to maximize the similarity between the positive pairs and minimize the similarity with the negative examples as regular.
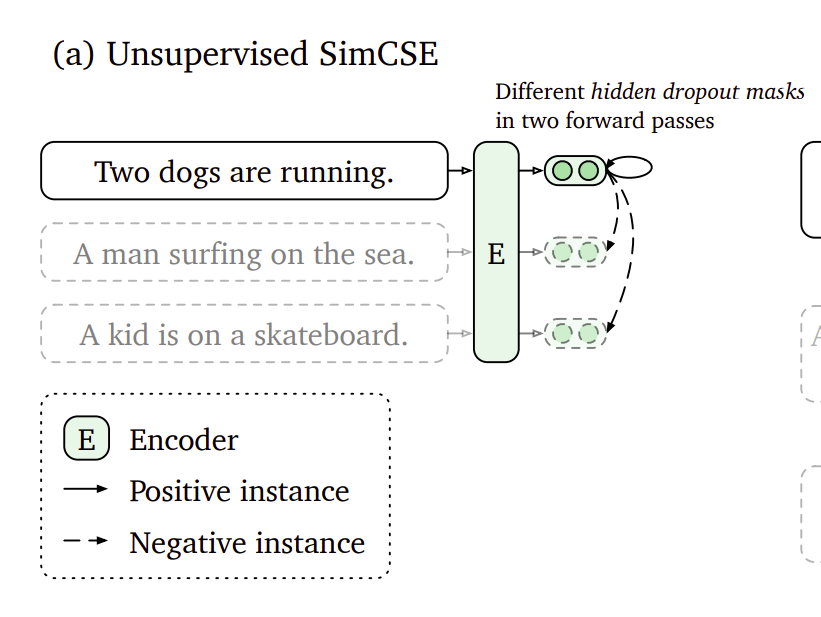
To achieve this finetuning, we need to:
- Prepare the training data.
- Load the finetuned version of the model from the BiMNTP training.
- Train the model using the SimCSE loss.
- Save the model.
Let’s get started!
Preparing the training data
The first step is to prepare the training data. We will use the same dataset as in the BiMNTP training - the Bulgarian Wikipedia. However, this time we need to yield pairs of sentences instead of single sentences. We will use a simple PairedDataset class to achieve this.
class PairedDataset(Dataset):
def __init__(self, data:Dataset):
self.data = []
for i, t in enumerate(data['text']):
self.data.append(DataSample(id_=i, query=t, positive=t))
def load_data(self, file_path: str = None):
pass
def __len__(self):
return len(self.data)
def __getitem__(self, index):
sample = self.data[index]
return TrainSample(texts=[sample.query, sample.positive], label=1.0)
Note how the PairedDataset class takes a Dataset object and saves a list of DataSample objects with the same text for query and positive.
Afterwards, the __getitem__ method returns a TrainSample object with the query and positive texts and a label of 1.0.
To use this, we can load the raw dataset as before and then create a PairedDataset object:
datasets = load_raw_datasets(data_args, model_args)
train_dataset = PairedDataset(datasets['train'])
valid_dataset = PairedDataset(datasets['validation'])
train_examples = [train_dataset[i]
for i in tqdm(range(len(train_dataset)),desc="Loading train examples...",disable=not accelerator.is_main_process)
]
validation_examples = [
valid_dataset[i]
for i in tqdm(
range(len(valid_dataset)),
desc="Loading train examples...",
disable=not accelerator.is_main_process,
)
]
Load the finetuned model
First, we need to load the finetuned model from the BiMNTP training. We will use the LLM2Vec class to do this.
from llm2vec import LLM2Vec
model = LLM2Vec.from_pretrained(
base_model_name_or_path=model_args.model_name_or_path, # the original model "INSAIT-Institute/BgGPT-7B-Instruct-v0.2"
enable_bidirectional=model_args.bidirectional, # True
peft_model_name_or_path=model_args.peft_model_name_or_path, # the adapter model we finetuned in the previous post "mboyanov/bggpt-mntp"
merge_peft=True, # Merges the adapter with the base model to create a single model.
pooling_mode=model_args.pooling_mode, # mean
max_length=model_args.max_seq_length, # 512
torch_dtype=getattr(torch, model_args.torch_dtype), # bf16
attn_implementation=model_args.attn_implementation, # flash-attn2
attention_dropout=custom_args.simcse_dropout, # 0.8
)
model
> LLM2Vec(
(model): MistralBiModel(
(embed_tokens): Embedding(38000, 4096)
(layers): ModuleList(
(0-31): 32 x ModifiedMistralDecoderLayer(
(self_attn): ModifiedMistralFlashAttention2(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): MistralRotaryEmbedding()
)
(mlp): MistralMLP(
(gate_proj): Linear(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): MistralRMSNorm()
(post_attention_layernorm): MistralRMSNorm()
)
)
(norm): MistralRMSNorm()
)
)
Note that we are passing in both the base model and the PEFT adapter model which contains the finetuning we performed in the previous post.
We are also passing in the merge_peft=True argument to merge the PEFT adapter with the base model to create a single model. This way we ensure that
the Bi-MNTP fine-tuning is preserved as it is now frozen and incorporated into the base model.
The other important argument is the attention_dropout=custom_args.simcse_dropout. This will set the dropout rate for the attention layers in the model.
This is important because the SimCSE method relies on the model generating different embeddings for the same sentence by using different dropout masks.
Now that we instantiated the base model, we can initialise a new PEFT adapter that we will train in the current stage:
from bg2vec.model import initialize_peft
# model organization is LLM2VecModel.model -> HF Model, we have to apply PEFT to the inner model
model.model = initialize_peft(
model.model,
lora_r=custom_args.lora_r,
lora_alpha=2 * custom_args.lora_r,
lora_dropout=custom_args.lora_dropout,
)
Train the model
To train the model, we need to define a loss function, a collator and a trainer.
Let’s start with the loss function:
from llm2vec.loss.utils import load_loss
train_loss = load_loss(custom_args.loss_class, scale=custom_args.loss_scale)
train_loss
> <llm2vec.loss.HardNegativeNLLLoss.HardNegativeNLLLoss at 0x777d34f7b6d0>
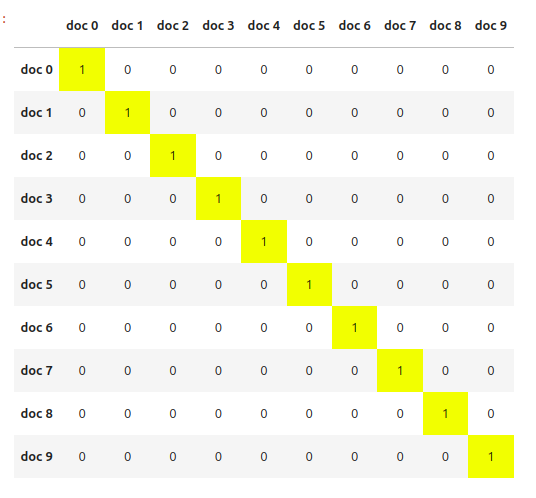
The loss function is quite interesting. It computes a square matrix of cosine similarities between all pairs of
embeddings in the batch. The diagonal of the matrix contains the similarities between the positive pairs while the rest of
the entries are the in-batch negatives. It then uses cross entropy loss passing in torch.arange(0, num_docs) as the target -
this way we mark the diagonal entries as the “correct class” in the cross entropy calculation.
Next, we need to define a collator. The collator is responsible for taking a list of TrainSample objects and converting them into a batch of tensors.
Since the TrainSample object contains raw texts, it needs access to the model tokenizer. Note that LLM2Vec has some custom tokenization logic,
so we need to pass in the model.tokenize function to the collator.
from bg2vec.training import SimCSEDefaultCollator
data_collator = SimCSEDefaultCollator(model.tokenize)
Finally, we can define the trainer and start training. Again, to replicate the LLM2Vec training, we train for a 1000 steps with a batch size of 128.
from bg2vec.training import SimCSETrainer, StopTrainingCallback
trainer = SimCSETrainer(
model=model,
args=training_args,
train_dataset=train_examples,
eval_dataset=validation_examples,
data_collator=data_collator,
tokenizer=model.tokenizer,
loss_function=train_loss,
)
if custom_args.stop_after_n_steps is not None:
trainer.add_callback(StopTrainingCallback(custom_args.stop_after_n_steps))
trainer.callback_handler.remove_callback(transformers.integrations.integration_utils.WandbCallback)
trainer.train()
And that’s it! We can save the model and use it for downstream tasks.
In fact, I have already trained the model and you can find it on the Hugging Face model hub as mboyanov/bg2vec.
To use it, you can simply load it as follows:
from llm2vec import LLM2Vec
model = LLM2Vec.from_pretrained("mboyanov/bg2vec")
model.encode(["Това е примерно изречение."])
> tensor([[-0.7892, -0.8819, 4.3372, ..., -2.1650, 0.0459, 3.4993]])
In the next post, we will evaluate if the model is performing better for similarity tasks compared to the original model.
Stay tuned!